Using deep learning to create personalized ads
I’ve finally managed to find some time to write a short post about our winning solution at the Telekom Leading Data Hackathon. The aim of this post is to give an example of how to use deep learning in a practical business use case.
Deep learning is a powerful method to solve highly non-linear, even ill-defined problems simply based on example. With recent developments of IT (i.e. increased computational power), this method become applicable to not only toy data, but to large scale real-world problems as well. Today, artificial neural networks are able to classify images close to human accuracy, can learn to segment a picture to individual objects, and even tell in plain English what we see on a photo. These are all groundbreaking results of extensive research practised by brilliant minds in the field. Nevertheless, companies still find it hard to integrate these solutions in their existing methodology or apply them to specific use cases. There are multiple factors behind this. I would like to cite two here. First, the function/mapping that a neural network learns is oftentimes very hard to understand not to say verbalise. Second, if we want a custom solution and not a canned (sorry trained) neural network then we need a lot of data… I mean a lot. of. data.
In this year’s data hackathon, we (Ádám Divák, Daniel Pálma and myself) endeavoured to use state of the art deep learning in the generation of a business insight. For those who are not working on the field, I would like to add that this was a 24 hrs long competition, which in “deep learning-time” is only a blink of an eye. Therefore we had to think and plan precisely what we want and can achieve in the given timeframe.
We have set up three goals, which could be generalised to most of the hackathons:
- Pitch-ready idea: this means our product had to be communicated in a sentence in a way not only data scientists but business executives would understand and can use.
- Money-maker: the audience should see the business value immediately in the product
- State-of-art/Fancy factor: the solution has to be better than the one which was available yesterday
In this competition, participants received sanitised call and internet usage logs from Telekom and were given freedom to try whatever they were interested. The expected output was some kind of business value.
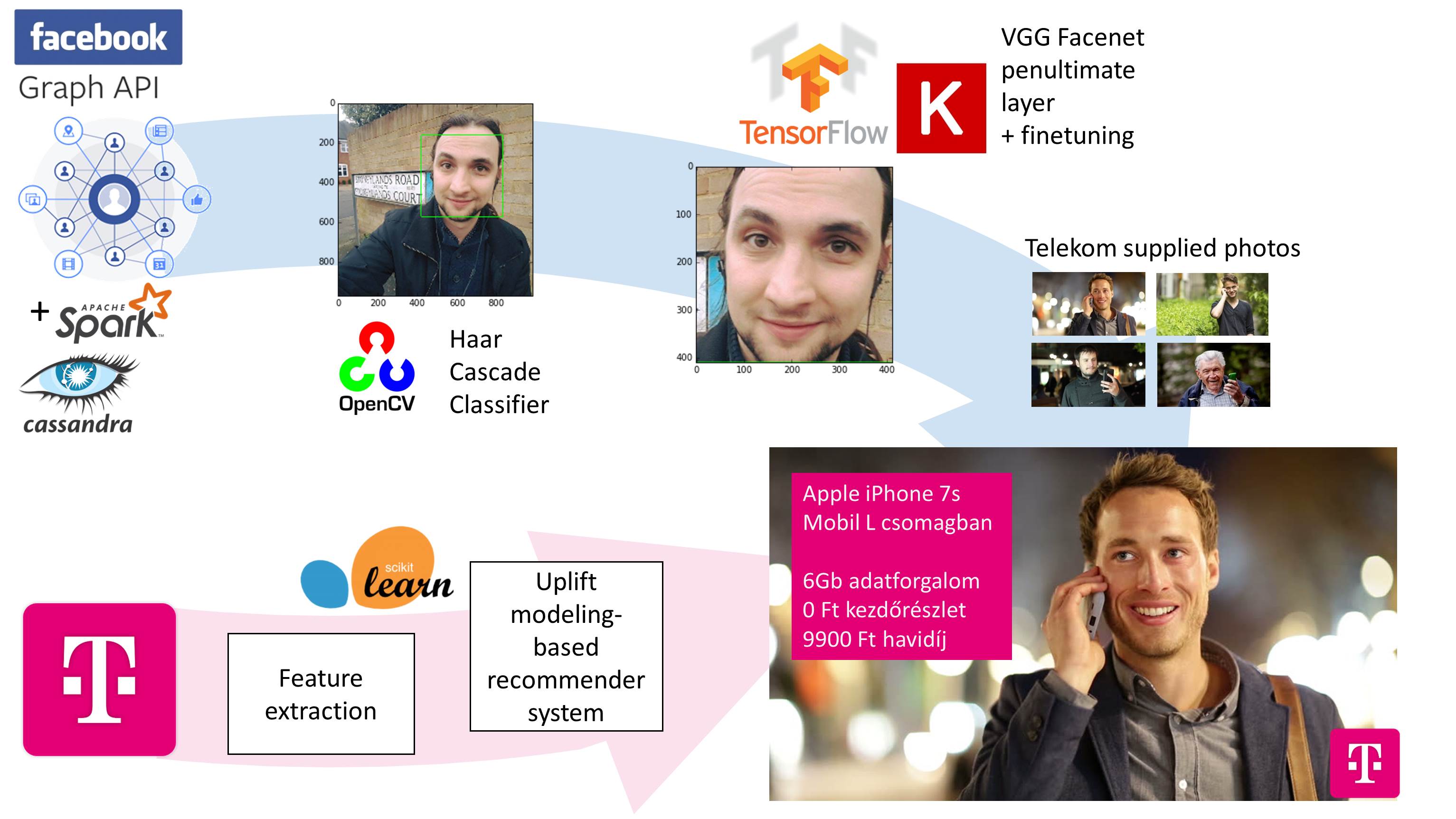
We started our work with a 3-hour long discussion. We went on a walk in the area and popped different ideas, some were interesting, some were easily communicated, others were profitable. After a while, we came up with an idea which promised to fulfil both of the three criteria we have set up. The core of this was that we should use the call logs (which contained the type of phones used to make the calls) to create personalised offers. For this purpose, we used uplift modelling to find meaningful associations between residence, age, phone manufacturer and next phone manufacturer. Using this technique we were able to show the strength of loyalty to manufacturers (Hola Apple ;) ); also by having more CRM data, this method could give even more interesting insights.
Of course, a personalised offer is worth nothing if the person is not willing to buy it. Therefore, we invested our remaining time and resources into creating a better advertisement.
Research tells that people like similar faces, even further, they not only like them but tend to trust them and pay attention to them more. So our idea was to use this result and find similar faces to ours in a simulated campaign photo inventory. For an example, we scraped my picture from facebook (if you are interested why from Facebook, I suggest listening to our talk at the Big Data Universe conference later that week). Then, using opencv, we detected and cropped the face from the picture. After having only the picture we took the penultimate layer of FaceNet to embed my face along with others in the inventory into a compact Euclidean coordinate system where we were able to find the most similar one to mine. This way we were able to present the offer crafted for my needs with the face most similar to mine. Impressive, isn’t it?
We pitched our solution to the jury which found ours the best in the competition. We are especially proud of this since there were at least two other teams with exceptional solutions.
Of course, at the end of the 24 hrs we also realised that this would be only the beginning of developing this product. Not only that a proper similarity requires some warping on the faces to make them all e.g. frontal and some fine-tuning in FaceNet, but we also have to maybe include e.g. hair colour, age etc. Furthermore, we started to think about that maybe not even the own face would be the most effective, but the face of the person with the biggest social impact in their social web. For this, we have to mine their connections… So it is so much you can de with machine learning and statistical tools.
Finally, as with previous hackathons I am more and more convinced that the most important thing is not the idea itself but the team, which is going to implement it. I really enjoyed working together with two of the smartest and most skilled data fellows, Ádám and Dani during the competition.